The Priority Queue: Always Serving the Most Important First
The Priority Queue: Always Serving the Most Important First
Earlier we tried to keep track of priorities using a linked list, and we saw that it just doesn't work well. Searching for the most important item over and over is slow. So instead of fighting with a tool that wasn't built for the job, we can use a data structure that was designed for exactly this: the priority queue.
A priority queue is a data structure built to keep track of the maximum (or minimum) of a dataset that keeps changing — items being added and removed all the time.
First, what is a regular queue?
Think of a line of people at a shop. The first person to join the line is the first person to be served. New people join at the back, and people are served from the front. This rule is called FIFO — *first in, first out*. The order is decided purely by who arrived first.
What makes a priority queue different?
A priority queue also has a front and a back:
- You insert new data at the back.
- You extract (remove) data from the front.
But here is the twist: a priority queue does not care who arrived first. It cares about importance. Every item you put in carries a number called its priority. The priority queue always keeps the highest-priority item at the front, ready to be served first — no matter when it arrived.
So the rules are:
- The item with the highest priority always comes out first.
- If two items have the same priority, then the older one comes out first (it falls back to FIFO for ties).
A helpful way to picture it: a regular queue is "first come, first served," while a priority queue is more like an emergency room — the most urgent case is seen first, even if it walked in last.
A real-life example: patients and doctors
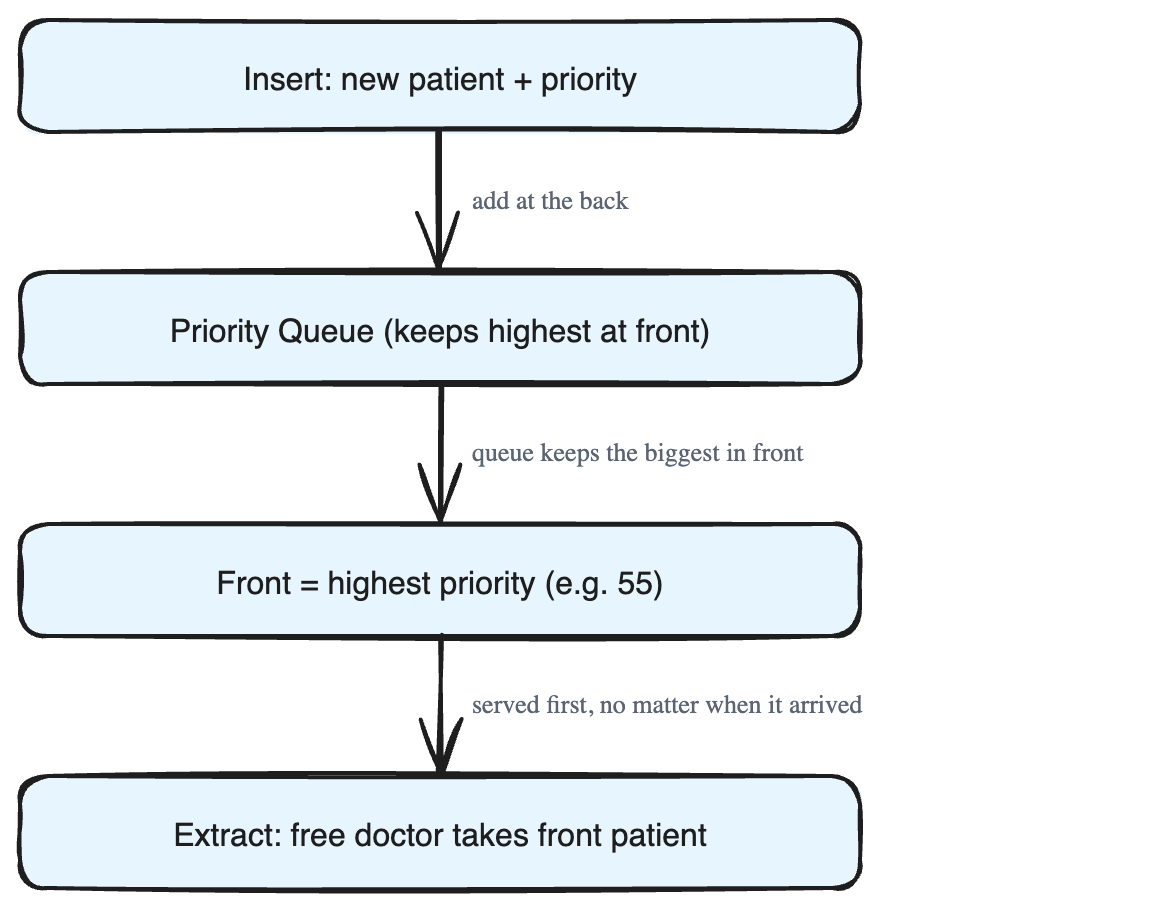
Imagine a hospital with a limited number of doctors — say doc1, doc2, and doc3 — and many patients arriving. Each patient is given a number that represents how urgent their case is. The bigger the number, the higher the priority.
We can solve this cleanly with a priority queue:
- When a new patient arrives: we push the patient (along with their priority number) into the priority queue.
- When a doctor becomes free: we extract the patient at the front of the queue and send them to that doctor.
The priority queue does the hard work for us. It guarantees that whenever we extract from the front, we get the patient with the highest priority at that moment.
Let's walk through a small story with priorities like 55, 15, 10, 22, 12, 50:
- A patient with priority
55is at the front because it is the largest number, so the first free doctor takes them. - After
55is removed, the queue rearranges so the next largest,50, moves to the front and is served next. - New patients keep arriving — for example, someone with priority
60walks in. Even though they came late,60is the new largest, so it becomes the front and is served before the smaller numbers waiting behind it.
Notice the key idea: we never had to manually search through everyone to find the most urgent patient. The priority queue always kept the largest at the front for us.
The big picture
A priority queue is a powerful tool that scales to handle huge, constantly changing datasets. It is an abstract data type — meaning it describes *what the structure does* (serve the highest priority first), not *how* it is built inside. It can be built in several ways:
- sorted arrays
- self-balancing search trees
- and others
Each way has its own trade-offs — some make inserting fast, others make extracting fast. Later in the course, we will learn the most popular and efficient way to build one: using a heap.