Why We Need a Priority Data Structure (The Problem Behind Heaps)
Why We Need a Priority Data Structure
Before learning what a *heap* is, it helps to first feel the problem that a heap was invented to solve. Once you see the pain, the solution makes a lot more sense.
The kind of problem we are talking about
Sometimes a program needs a data store (a place to keep data) that is smart in one specific way: at every moment, it should know the smallest or largest item it is holding. And it should do two things very fast:
- Insert a new item.
- Take out the current minimum or maximum.
If both of these are quick even when there are millions of items, life is good.
A real-world picture: the hospital emergency ward
Imagine an emergency ward with only a few doctors but many patients. Each patient is given a priority number based on how serious their case is. A bigger number means a more urgent patient.
In our example the waiting patients have priorities:
15, 10, 22, 12, 50, 55
Here is the rule:
- New patients keep arriving (we need fast insert).
- Whenever a doctor becomes free, we hand them the patient with the highest priority right now (we need fast find-and-remove-the-max).
So when doc1 becomes free, the patient with priority 55 should be picked. Then when another doctor is free, 50 is next, and so on. If a new patient with priority 60 walks in, they should jump ahead of everyone, because 60 is now the largest.
This "always serve the most urgent first" idea is called a priority queue. It is a queue where position depends on priority, not on who arrived first.
First attempt: store everything in a linked list
A natural first idea is a linked list. A linked list is a chain of boxes called *nodes*. Each node holds one patient's data (name and priority) and a next pointer that points to the following node. The very first node is reached through a pointer called head, and the last node's next points to null (meaning "end of the chain").
So our patients become:
head -> 15 -> 10 -> 22 -> 12 -> 50 -> 55 -> nullInserting a new patient is fast
When a new patient with priority 60 arrives, we do not need to find a special spot. We just stick the new node at the front (the head) of the list and point it to the old head:
head -> 60 -> 15 -> 10 -> 22 -> 12 -> 50 -> 55 -> nullThis takes the same tiny amount of time no matter how long the list is. We call this a constant-time operation (often written as O(1)) — the cost does not grow with the number of patients. So far, so good.
The painful part: finding and removing the maximum
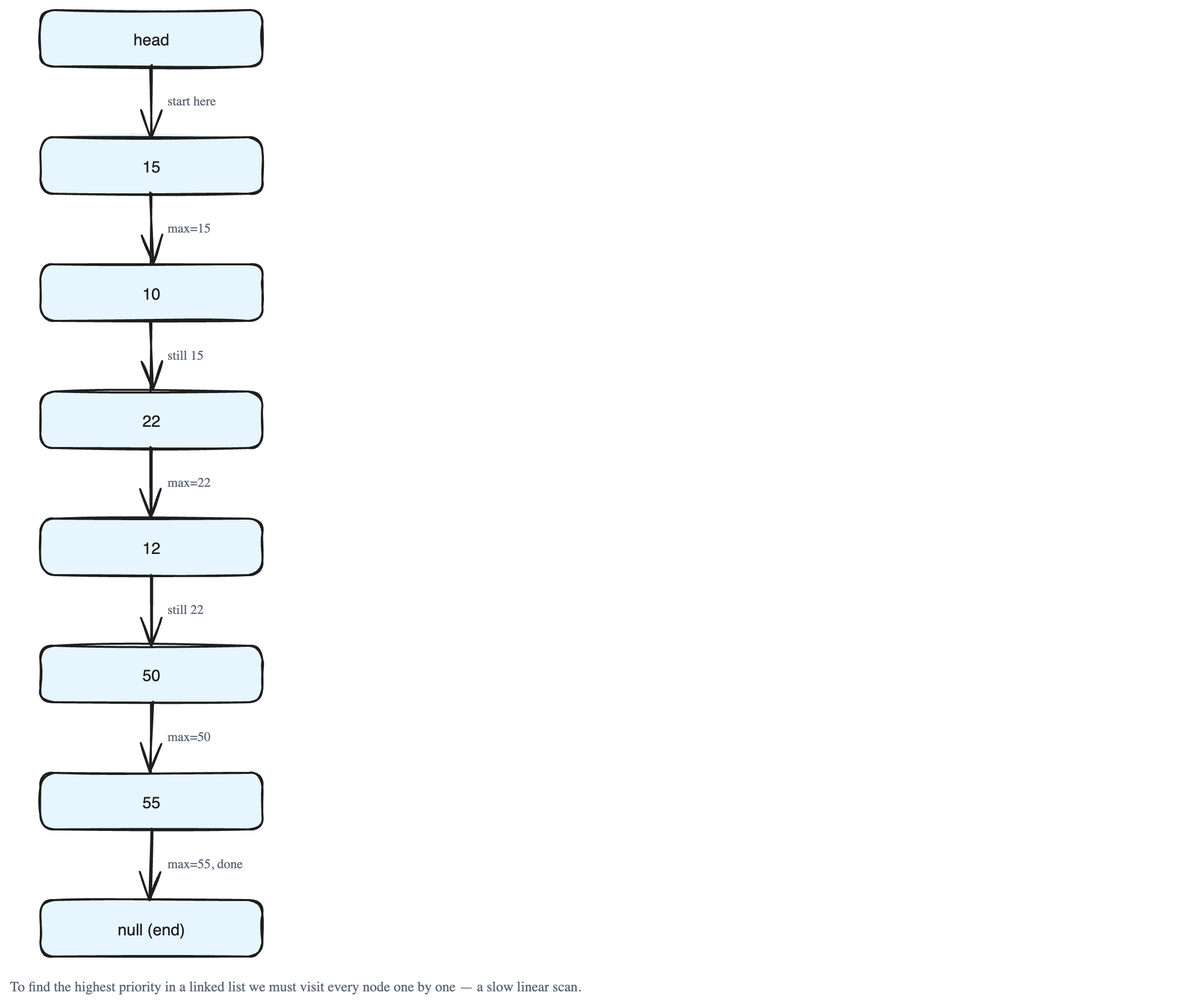
Now a doctor becomes free and we must pull out the patient with the highest priority. The problem is that the list is not sorted. The biggest value could be anywhere.
So we have to walk through the whole chain, one node at a time, keeping track of the biggest value seen so far. Step by step, using a current pointer and a max variable:
- Start at
15. So farmax = 15. - Move to
10. Stillmax = 15. - Move to
22. Nowmax = 22. 12? Stillmax = 22.50? Nowmax = 50.55? Nowmax = 55.- Reach
null. The walk is over,max = 55.
Only after touching every single node do we know the answer is 55. Then we remove that node. This full walk through the list is called a linear scan, and its cost grows with the number of patients (written as O(n), where n is how many items there are).
Why this is not good enough
For a handful of patients, a linear scan is fine. But the operation we do most often — find the max and take it out — is also the slow one. Now scale the idea up. Picture a country-wide emergency service like 911, with hundreds of thousands of active cases. Scanning the whole list every single time a responder frees up would be painfully slow.
The textbook sums up two clear weaknesses of the linked-list approach:
- Extra space: every node must store extra
next(and sometimesprevious) pointers just to stay linked together. - Poor performance: finding and extracting the min/max needs a linear scan of all items, so the most common action is the most expensive one.
So what do we actually want?
We want a data structure that gives us the best of both worlds:
- Insert a new item quickly.
- Get and remove the maximum (or minimum) quickly — without scanning everything.
A plain linked list gives us fast insert but slow extract. Keeping the list fully sorted would give fast extract but slow insert. Neither is great. What we really want is a structure that stays *just organized enough* to always know its top item, without paying to keep everything perfectly sorted.
That "magical" structure exists. It is called a heap, and it is exactly what the rest of this course will build. For now, the key takeaway is the problem itself: we need fast inserts and fast access to the largest (or smallest) element at the same time.