How an Interpreter Runs Your Code: From Source Text to Action
How an Interpreter Runs Your Code
When you write a program, the computer cannot understand your text directly. The words x = x + 5 mean something to you, but to the machine they are just letters and symbols. Something has to translate your code into actions the computer can perform.
There are two main ways this happens.
- Compiled languages translate the whole program into machine code *before* it runs. The translation is done once, ahead of time, and then the finished machine program runs on its own.
- Interpreted languages like Python and JavaScript do *not* build a separate machine program. Instead, a special program called an interpreter reads your code step by step, figures out what each part means, and runs it right away.
This makes interpreted languages very flexible and easy to change. The trade-off is that they are often slower, because the translating work happens *while* the program is running, not before.
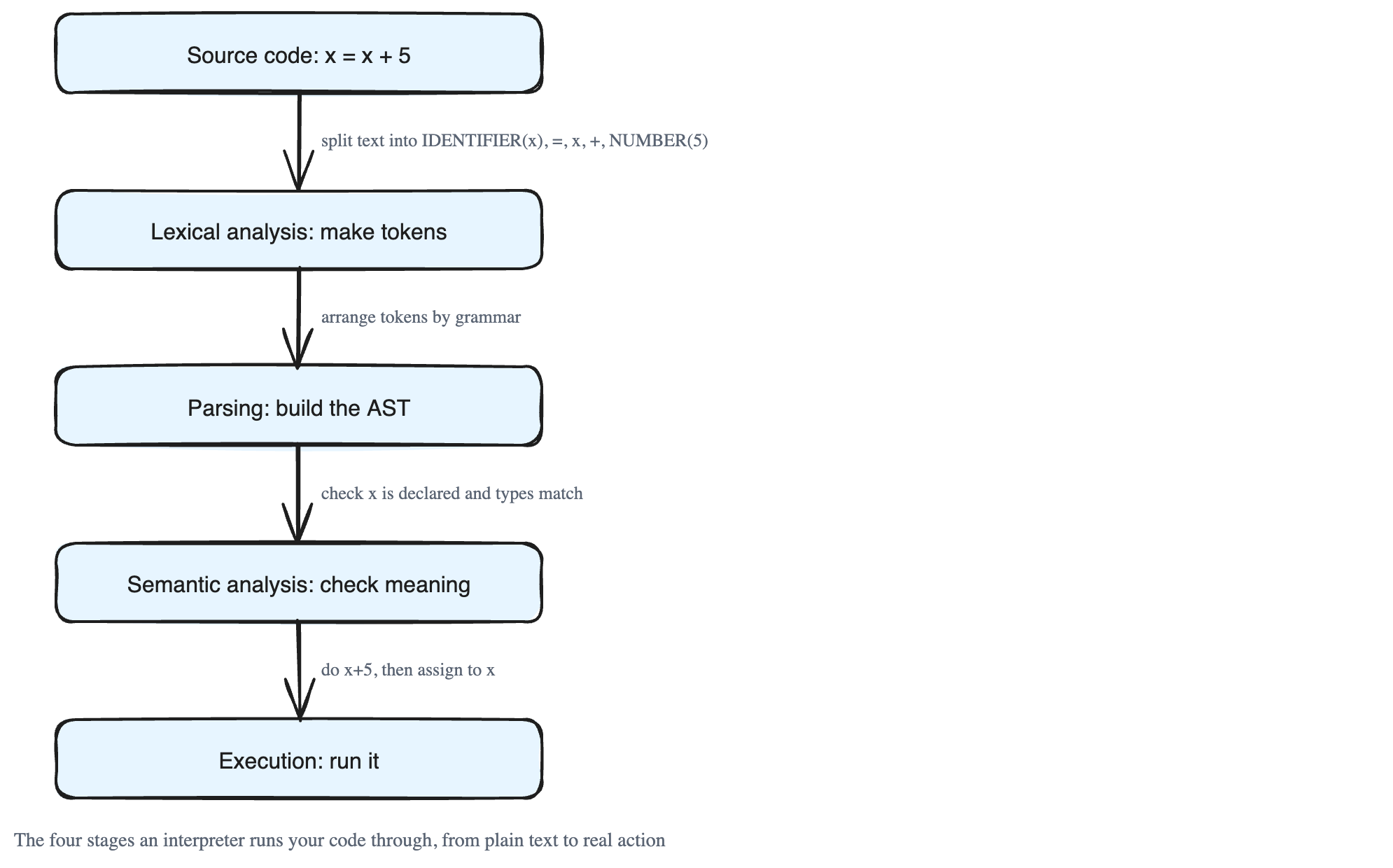
Let's follow one simple line of code through the whole journey:
// Example code line to interpret
x = x + 5The interpreter does several jobs to run this line: lexical analysis, parsing, semantic analysis, and finally execution. We'll walk through each one.
Step 1: Lexical Analysis (Tokenisation)
The first job is to read the raw text and break it into small meaningful pieces called tokens. Think of how you read a sentence: you don't read it letter by letter, you see whole words. The interpreter does the same. It scans the code from left to right and groups characters into useful chunks.
The kinds of tokens it looks for include:
- Keywords — special reserved words like
iforwhile. - Identifiers — names you create, such as variable names and function names.
- Operators — symbols that do something, like
+or==. - Literals — fixed values written directly in the code, like numbers or text strings.
For the line x = x + 5, the interpreter (here called the lexer) produces these tokens:
IDENTIFIER(x) ASSIGNMENT(=) IDENTIFIER(x) PLUS(+) NUMBER(5)A few helpful details:
- Things that don't affect how the code runs — like extra spaces, blank lines, and comments — are usually thrown away during this step.
- In Python, spacing matters, because indentation marks where blocks of code begin and end. So the lexer there has to carefully track indentation levels.
- This step also catches early mistakes, such as a strange character that doesn't belong or a badly written number. Catching them now stops broken code from moving forward.
By turning a stream of plain text into a tidy list of tokens, the interpreter makes the rest of the work much simpler.
Step 2: Syntax Analysis (Parsing)
Now the interpreter has a list of tokens, but a list alone doesn't tell us how the pieces relate. Parsing checks whether the tokens are arranged in a valid order according to the language's grammar (its rules for how code must be written).
If something is out of place — a missing parenthesis, an operator in the wrong spot, or a half-finished statement — the parser reports a syntax error and stops *before* the program runs.
To capture how the pieces fit together, the parser builds an Abstract Syntax Tree (AST). The AST is a tree shape that shows the logical structure of the code: which operation happens first, and how the parts are grouped.
For x = x + 5, the AST looks like this:
=
/ \
x +
/ \
x 5Reading the tree tells a clear story: first do x + 5, then assign that result to x. The tree shape captures the correct order of operations automatically, so nothing is left to guesswork.
Step 3: Semantic Analysis
A program can follow all the grammar rules and *still* make no sense. For example, the sentence "the number five ate a song" is grammatically fine but meaningless. Semantic analysis checks for meaning, not just structure.
This step makes sure the code is *logically* valid. It handles things like:
- Type checking — making sure values are used in sensible ways (you can add a number to a number, but not a number to a sentence).
- Making sure a variable is declared before it is used.
- Confirming that function calls give the right number and kind of arguments.
For x = x + 5, semantic analysis confirms that x actually exists in the current scope, and that adding 5 to it is allowed for its data type.
The checks for this line, in order:
- The left side,
x, is looked up in the symbol table to confirm it is declared and that its type matches the right-hand side. - The
+operation is checked to make sure both sides are compatible types (number+number). - The result type of the expression matches the type of
x, so the assignment is valid.
A check mark (✔) means a part passed its semantic check. So in our example, both IDENTIFIER(x) (declared, type number) and LITERAL(5) pass. By contrast, assigning a string to an integer, or using a variable that was never defined, would fail right here — even though the grammar looked perfectly fine.
While doing this, the interpreter also builds symbol tables: records that track every variable and function, their types, and where they are visible (their scope). These tables let the interpreter quickly look up names later and avoid conflicts or undefined values.
Step 4: Execution
Once the code has passed syntax and semantic checks, the interpreter finally runs it. There are two common ways to do this.
1. Direct execution
The interpreter evaluates the program line by line, using the AST or token stream. Each statement runs immediately, variables update on the fly, and output appears as the code runs. The flow is simple:
Source code -> Platform independent interpreter -> Machine code (actions)The big advantage is fast testing and debugging: you change the code and run it instantly, with no separate build step. Languages that commonly use direct execution include JavaScript (in browsers), Ruby, and PHP.
2. Bytecode execution
Here the interpreter first translates the source code into an in-between form called bytecode — a lower-level representation that does not depend on any specific computer. The bytecode is then run by a virtual machine (VM):
Source code -> Platform independent interpreter -> Bytecode -> Platform dependent virtual machine -> Machine code (actions)This is usually more efficient. The VM can optimise how things run, reuse the bytecode across multiple runs, and avoid repeating the slow parsing work every time. Languages that use bytecode execution include Python (CPython), Java (compiled to JVM bytecode), and C# (compiled to .NET IL).
Putting It All Together
Both execution styles end up doing the same thing: turning your human-readable instructions into real actions the computer performs — calculations, function calls, and input/output. The full pipeline an interpreter follows is:
read text → break into tokens → check the structure → check the meaning → run it.
Each stage hands cleaner, more organised information to the next, so that by the time your code actually runs, the interpreter is working with clear, well-formed instructions instead of raw, messy text.