Defining a Hash Function
Defining a Hash Function
A hash function sits at the heart of every hash table. Before we look at how a hash table works inside, we need to really understand what a hash function is. And to do that, we first need to understand a plain old mathematical function.
What is a mathematical function?
Think of a function as a simple rule that takes something in and gives one thing back. You put a value in, and you always get exactly one value out.
In math language, a function goes from a set K to a set V:
Kis called the domain — the set of all values you are allowed to put *in*.Vis called the codomain — the set of all values that can come *out*.
The rule promises one important thing: every value in K is assigned exactly one value in V. Same input, same output, every single time.
These sets can hold any type of data — numbers, text strings, whole objects, anything.
Here are three simple number functions to make this concrete:
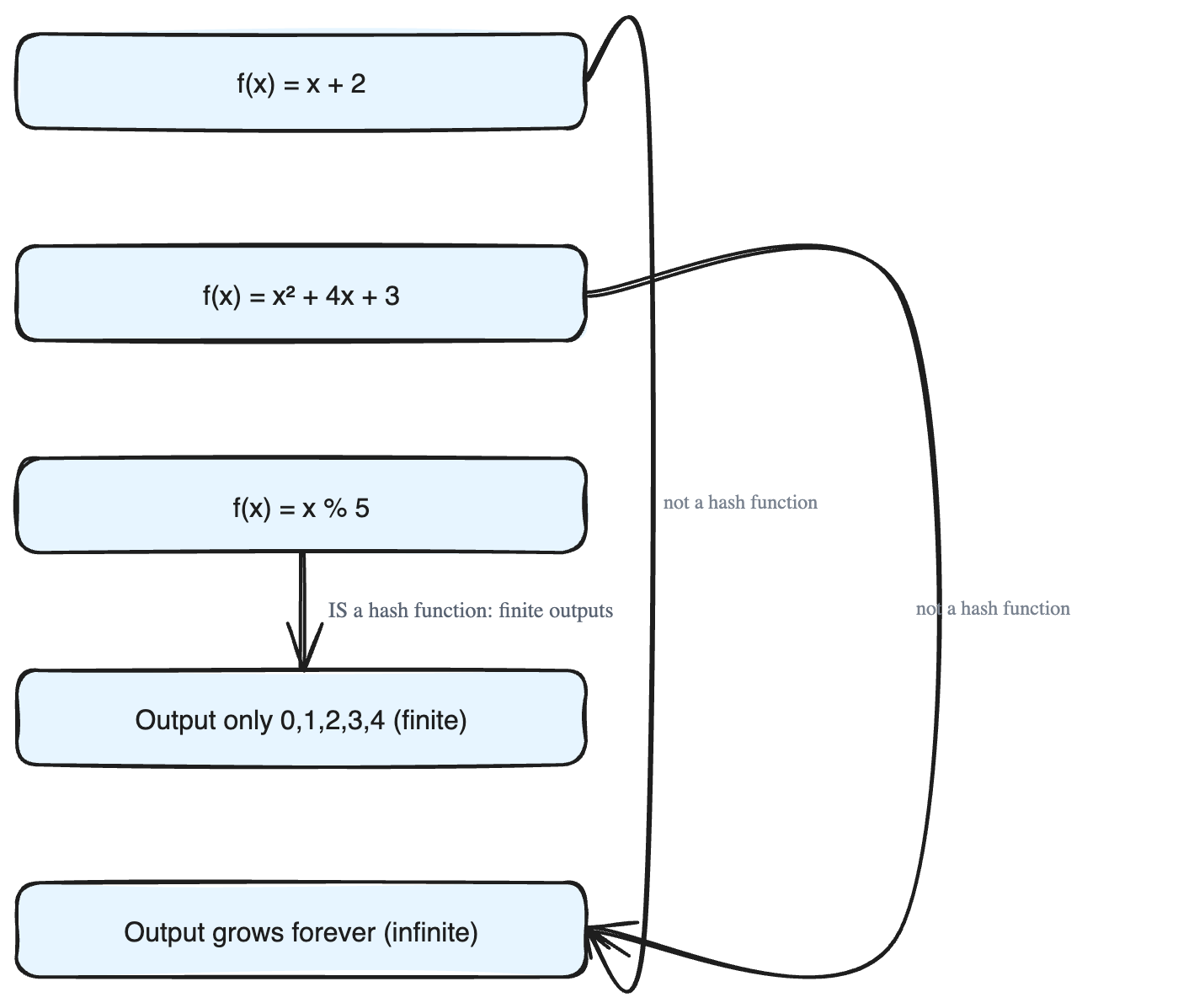
f(x) = x + 2f(x) = x² + 4x + 3f(x) = x % 5
A normal math function puts no limit on the size of its domain or codomain. Both can be small and fixed, or endlessly large (infinite). For example, f(x) = x + 2 can take any number you imagine, and it can also produce any number — both sides are infinite.
What makes a hash function special?
A hash function is just a special kind of mathematical function. Here is the one rule that makes it special:
> A hash function can take inputs from a set of *any* size (even infinite), but its outputs must come from a finite set — a set with a fixed, limited number of values.
So:
- The domain (the inputs, called keys) can be infinite or fixed.
- The codomain (the outputs) must be finite. These outputs are called hash values (also known as hash codes, digests, or just hashes).
This means every hash function is a mathematical function, but not every mathematical function is a hash function. Hash functions are a small group living inside the larger world of all functions.
Let's test our three examples:
f(x) = x + 2→ output grows forever asxgrows, so the output set is infinite. Not a hash function.f(x) = x² + 4x + 3→ same problem, the output keeps growing. Not a hash function.f(x) = x % 5→ the remainder when you divide by 5 can only ever be0,1,2,3, or4. That is a fixed, finite set of just 5 possible outputs. This one is a hash function!
The % (modulo) example is the key idea: no matter how huge the input number is, you are always squeezed into one of only 5 buckets.
Collisions: the unavoidable problem
Now think carefully. A hash function can have an infinite number of possible inputs, but only a finite number of possible outputs. If you keep pouring more and more inputs into a small number of output slots, some of them are forced to land on the same slot.
When two different inputs produce the same hash value, we call this a collision.
A quick example with f(x) = x % 5:
f(7) = 2f(12) = 2
Two different keys, 7 and 12, both map to 2. That's a collision.
Here is the important takeaway: collisions are inevitable. No matter how clever your hash function is, mapping infinitely many keys into a finite space *must* cause some overlaps. You cannot make collisions disappear completely.
But you are not helpless. You can choose your hash function carefully to make collisions rare. So what does a good hash function look like?
- It has a low chance of collision — it spreads inputs evenly across the output slots.
- It is fast — it computes the hash value quickly.
Keep these two goals in mind. They will guide everything we do when we build real hash tables next.