Why We Need Graphs: The Travel Booking Problem
Why We Need Graphs: The Travel Booking Problem
Before we learn what a graph is, let's understand *why* graphs even exist. The best way to do this is to look at a real problem that older, simpler data structures cannot handle well.
What data structures do for us
A data structure is just a way to store data so we can find it and use it again easily. There are two big families we have seen so far:
- Linear data structures store data one item after another, in a line. Arrays, linked lists, stacks, and queues all work this way. Think of items standing in a single queue, one behind the other.
- Hierarchical data structures store data in levels, like a family tree. Binary trees and heaps work this way. Every item has one parent above it and some children below it.
These two families are great for many jobs. But they share a hidden limit: they are good at simple relationships. A tree, for example, can show a parent-and-child link, but each child has only one parent. Real life is often messier than that.
A relationship trees cannot model
Many real problems need many-to-many relationships. This means one item can be connected to many others, and those others can connect back to many more — in any direction, with no clear "top" or "bottom."
A tree cannot do this. To see why, let's build something real.
The travel booking website
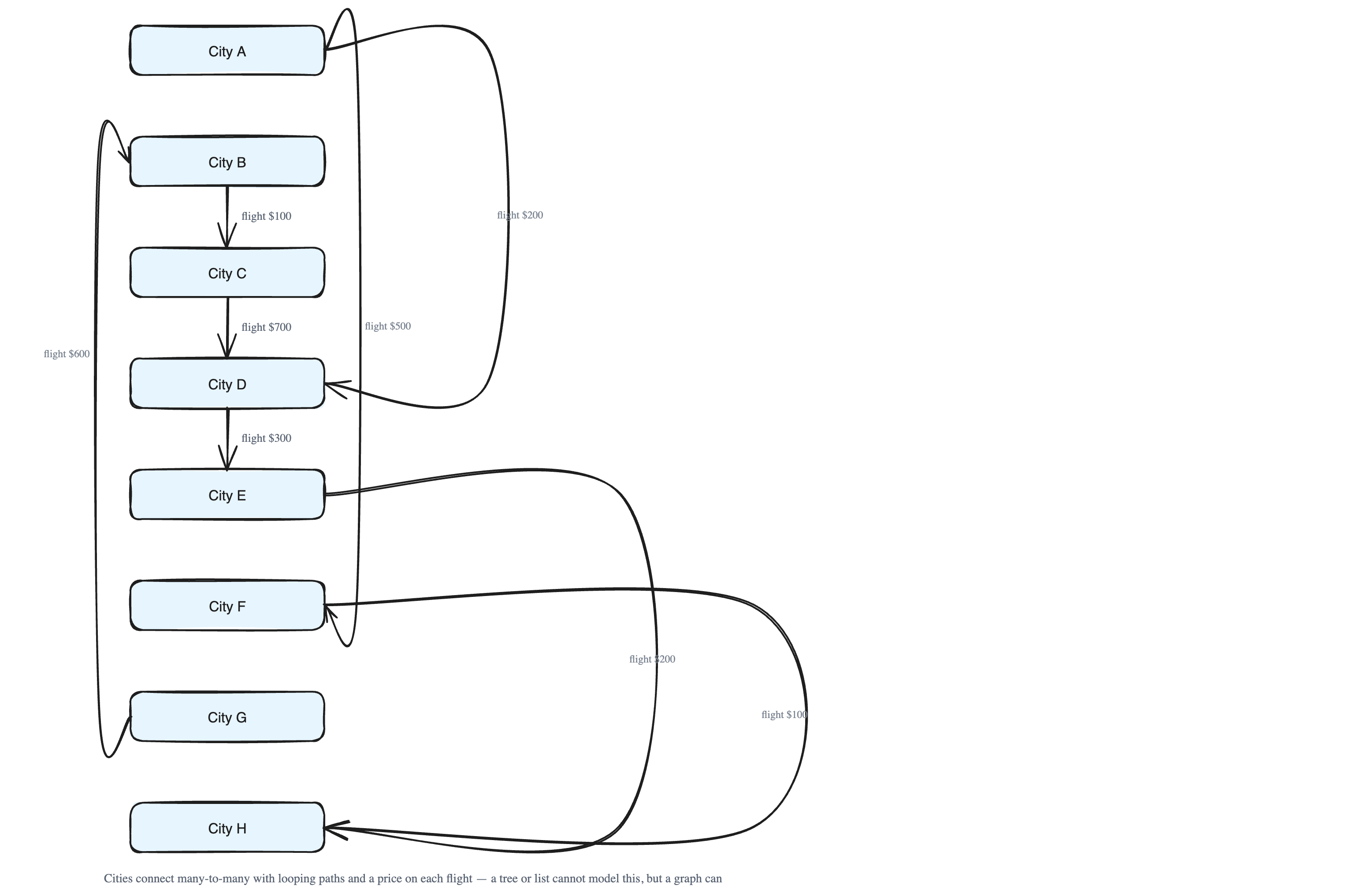
Imagine we want to build a travel website that shows flight connections between cities. Our raw data is just a list of which city flies to which city:
- City A → City F
- City A → City D
- City G → City B
- City B → City C
- City D → City E
- City E → City H
- City F → City H
- City C → City D
Notice the shape of this. City A connects to two cities (F and D). City D is reached from A and from C, and it also flies to E. The connections loop around and cross each other. There is no single "root" city and no neat parent-child layers. This is a many-to-many web of links.
We want our website to answer two kinds of user questions. Let's look at both and see where our old tools fail.
Problem 1: Find the minimum hops between two cities
A user types in their current city and their destination city. We want to tell them the smallest number of flights (hops) to get there.
For example, going from City A to City H:
- A → F → H is 2 hops.
- A → D → E → H is 3 hops.
So the best answer is 2 hops. To find this, a computer must explore all the paths and pick the shortest one.
Can a tree store this? No. A tree must be acyclic, which means it is not allowed to have cycles (loops that come back to where they started). But our flight data *has* cycles — you can leave a city and, through other cities, come back to it. By its very definition, a tree forbids this, so the data simply does not fit.
What about linked lists? One idea is to store each connection as a tiny linked list of two cities, like this:
A next F next head null
A next D next head null
G next B next head null
B next C next head null
D next E next head null
E next H next head null
F next H next head null
C next D next head nullEach little list holds two cities and the link between them. This *can* store the data — but answering "what is the shortest route from A to H?" now needs a slow, complicated algorithm. The computer would have to dig through every separate list again and again to follow a path. It works, but it is inefficient.
Problem 2: Find the most flights for a given budget
Now we add prices. Each connection also has an airfare:
- A → F costs
500 - A → D costs
200 - G → B costs
600 - B → C costs
100 - D → E costs
300 - E → H costs
200 - F → H costs
100 - C → D costs
700
A user gives us a starting city and an amount of money. We want to tell them the maximum number of flights they can take without going over their budget. Here the destination does not matter — we only care about flying as much as possible for the money they have.
This is even harder. Now every connection carries two pieces of information: which cities it links *and* how much it costs. Neither a plain linked list nor a tree gives us a clean place to store that extra cost on each link, and exploring all the money-spending paths quickly becomes a mess.
The takeaway
We have a kind of data that is:
- Many-to-many — any city can connect to any number of other cities.
- Possibly cyclic — paths can loop back on themselves.
- Carrying extra info on each connection — like a price.
None of our linear structures (arrays, lists, stacks, queues) and none of our hierarchical structures (trees, heaps) can model and store this data both *easily* and *efficiently*. We are missing the right tool.
That missing tool is the graph — a data structure built exactly for connections like these. In the next lessons, we will see how a graph stores cities and flights naturally, and how it answers both of these questions efficiently.