Why Singly Linked Lists Fall Short: The Problem That Leads to Doubly Linked Lists
Why Singly Linked Lists Fall Short
A singly linked list is a chain of boxes called nodes. Each node holds some data and a next pointer that points to the box right after it. The chain has a Head ptr (a pointer to the first node), and the last node points to nullptr, which simply means "nothing comes after me."
This design is great in many ways, but it has one big weakness: every node can only look forward. A node knows who comes *after* it, but has no idea who comes *before* it. That one missing piece of information makes some everyday operations slow and clumsy.
Let's see why, using a class of students stored in a singly linked list:
Ram → Shyam → Hari → Krishna → Neha → Nirav → nullptr
Problem 1: Deleting a node is slow
Imagine Neha leaves the class. We want to remove her node. You might think: "We already know exactly where Neha's node is, so deleting it should be instant." Sadly, it is not.
Here is the catch. To remove a node, we must reconnect the chain so it skips over the deleted node. That means the node one step before Neha must change its next pointer to point to the node after Neha. So we really need the *previous* node, not Neha's node.
But Neha's node cannot tell us who comes before her — she only points forward. So we are forced to start at the Head and walk through the list one node at a time, dragging a previous pointer along, until we find the node sitting just before her.
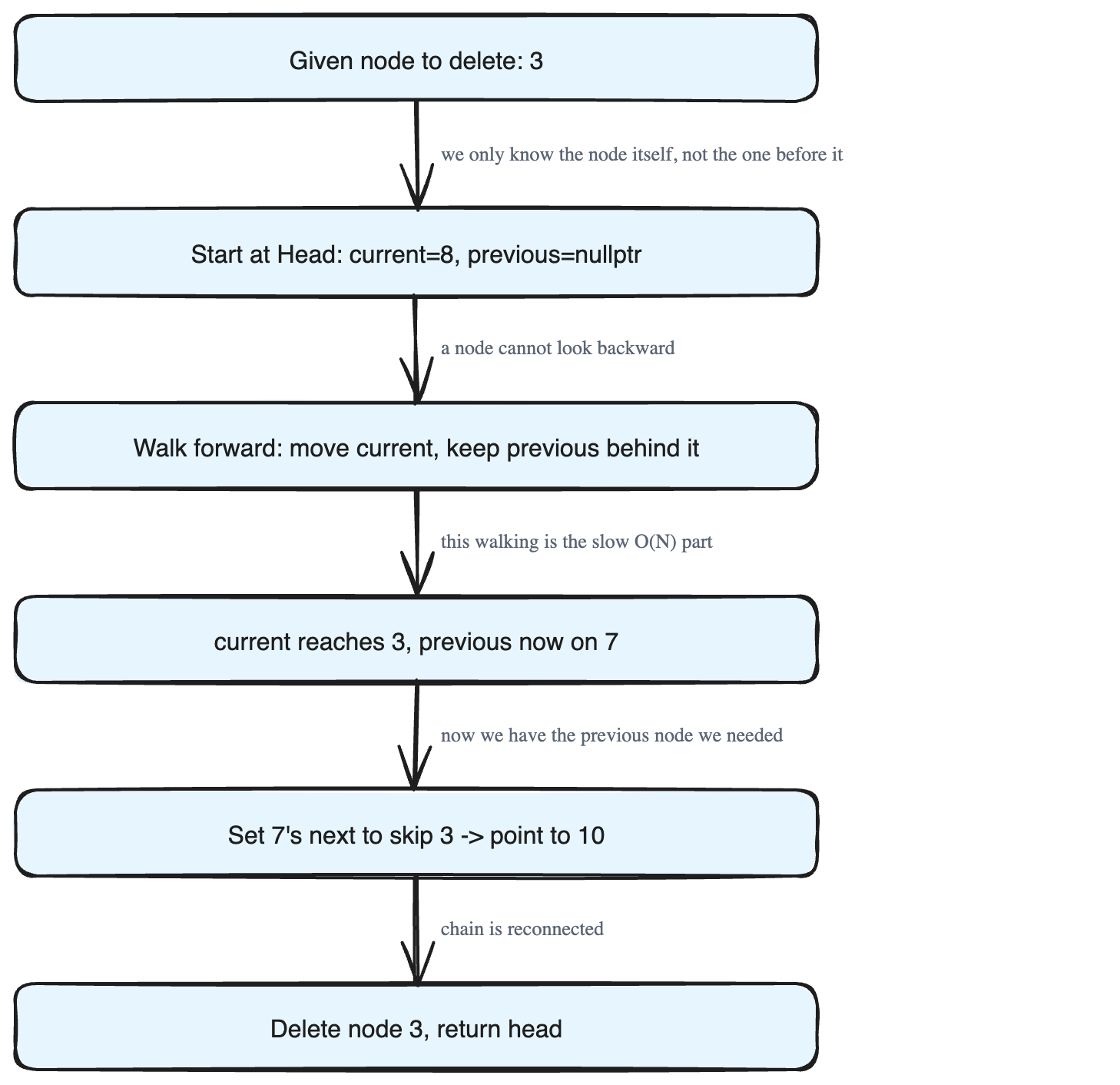
Let's trace this on a small list with values 8 → 5 → 7 → 3 → 10 → nullptr, where we want to delete the node 3:
- Start with
currentat the head (8) andpreviousset tonullptr. - Walk forward. Move
currentone node at a time. At each step,previousis left pointing at the nodecurrentjust came from. - Keep going until
currentlands on the target node3. Nowpreviousis sitting on7— exactly the node we needed. - Update the previous node's
next. Make7'snextpointer skip3and point straight to10. - Delete the
3node (free its memory). - Return the original head so the rest of the list stays usable.
The expensive part is step 2 — the walking. If the node we want is near the end, we travel almost the whole list to reach the node before it.
> In the worst case this takes O(N) time, where N is the number of nodes. For a tiny list that's fine, but for a list with millions of nodes, walking the whole thing just to delete one node is very wasteful.
Problem 2: Inserting *before* a node is slow too
Now suppose a new student, Anmol, joins and we want to place her node before Hari. Same trouble appears.
To insert a node before Hari, we must change Hari's *previous* node so its next points to Anmol's new node, and Anmol's next points to Hari. Once again, we need the node one step before the target — and once again, a singly linked list can't hand it to us directly.
Tracing the insert of a new node 8 before a given node in 5 → 7 → 3 → 10:
- Create the new node holding
8. - Search from the head with
currentandprevious, walking forward untilcurrentreaches the given node —previousnow holds the node just before it. - Point the new node forward: set the new node's
nextto the given node. - Point the previous node to the new node: set
previous'snextto the new node. - Return the original head.
Just like deletion, step 2 (the search) is the slow part, giving this a worst-case time of O(N).
The root cause
Notice the same villain in both stories: we cannot reach the node before a given node without traversing the list from the start. A singly linked node only stores a forward link, so going "one step back" is impossible without re-walking everything.
Because of this single limitation, these common operations all perform poorly:
- Insert at end
- Insert before a given node
- Delete the last node
- Delete a given node
- Delete the node before a given node
Each of them needs the *previous* node, and each is forced into an O(N) traversal to get it.
Where this leads
So the natural question is: what if each node could also remember who comes before it? If every node stored a backward link as well as a forward link, we could step backward instantly and make all of these operations fast. That idea is exactly what the doubly linked list is built on — and it's the data structure we explore next.