Key Tree Terminologies
Key Tree Terminologies
A tree is a non-linear data structure. Unlike an array or a linked list, where items sit in one straight line, a tree spreads out in two dimensions — it can branch and grow in many shapes. Because of this freedom, two trees can look very different from each other.
To talk about these shapes clearly, we need a shared vocabulary. The words below let us describe and compare any tree precisely. They are not just for one kind of tree — they work for all trees (binary trees, binary search trees, n-ary trees, and so on).
Let's go through each term one at a time.
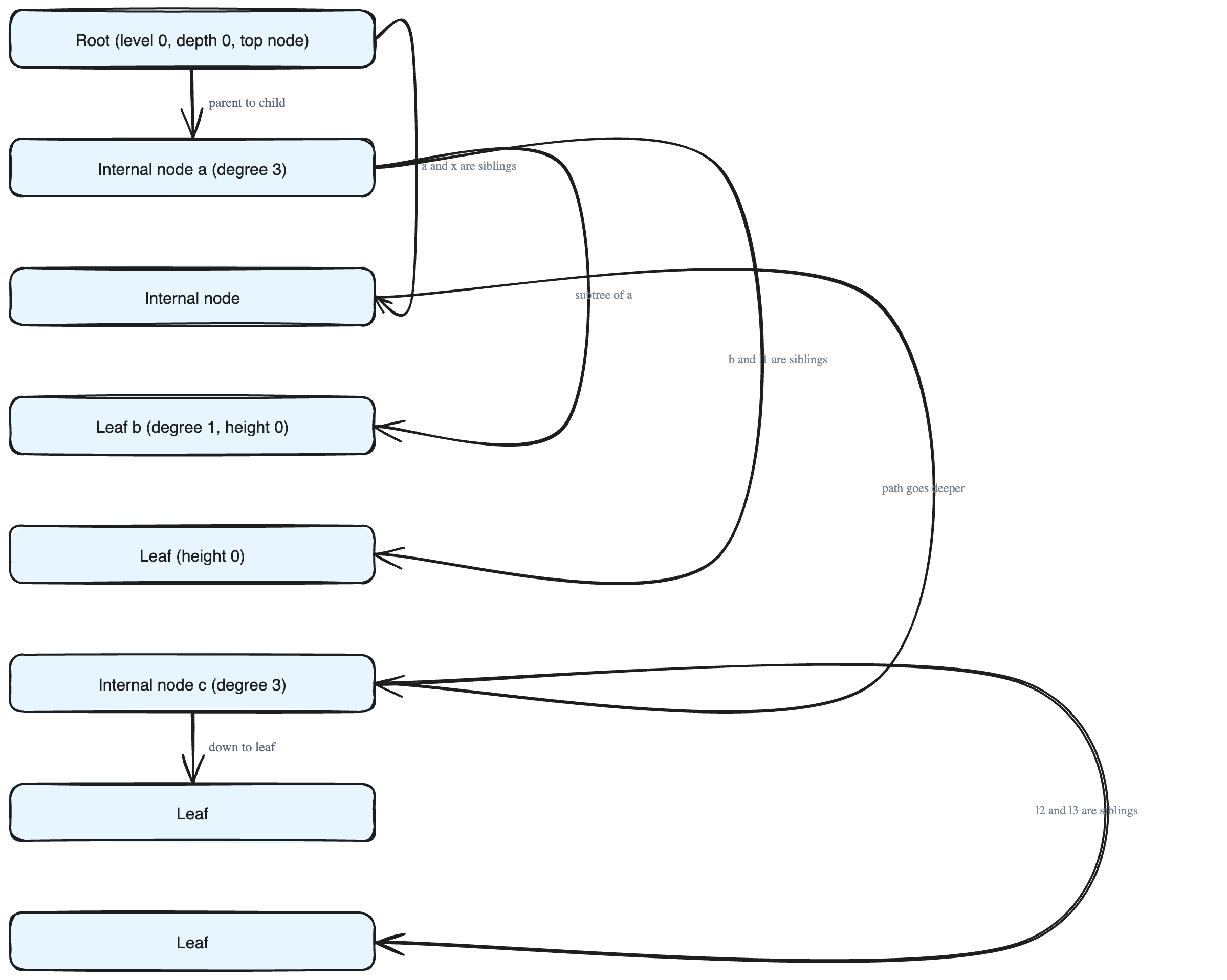
Root
The root is the single node at the very top of the tree. It is the only node that has no parent above it. Every other node in the tree can be reached by starting at the root and walking downward.
Think of it like the trunk of a real tree, except it sits at the top instead of the bottom. There is exactly one root in a tree.
Leaf
A leaf node is a node that has no children. These are the nodes at the very ends of the branches — nothing grows below them.
In the example tree, the bottom-most nodes (the colored ones) are leaves. A leaf is where a branch stops.
Internal Node
An internal node is any node that is not a leaf — in other words, a node that has at least one child. Every node except the leaves is an internal node. The root counts as an internal node too (as long as it has children).
So the whole tree splits into two groups: nodes with children (internal nodes) and nodes without children (leaves).
Degree
The degree of a node is the number of other nodes it is directly connected to by an edge.
Look at the example:
- Node
ais the root with three connections (to its children), sodegree of node a = 3. - Node
bconnects only to its parent, sodegree of node b = 1. - Node
cconnects to its parent plus its two children, sodegree of node c = 3.
Notice that for a node in the middle of the tree, the count includes the edge going up to its parent as well as the edges going down to its children.
Sibling
Siblings are nodes that share the same parent. They sit side by side, one level below their common parent.
If two nodes are children of the same node, they are siblings — just like brothers and sisters in a family who share the same parent.
Path
A path is the sequence of nodes and edges you travel through to get from one node to another. To find a path, you simply trace the connecting lines from the starting node to the ending node.
The length of a path is the total number of edges in it (not the number of nodes). For example, if you cross 2 edges to get from one node to another, the path length is 2.
Subtree
A subtree of a node a is a smaller tree made up of one of a's children plus everything below that child (all of its descendants).
Each child of a node starts its own subtree. So a node has exactly as many subtrees as it has children. For instance, the subtree of b is b together with all the nodes hanging below b.
This is a powerful idea: a tree is made of smaller trees inside it, and that "tree inside a tree" pattern is what makes many tree algorithms simple to write.
Level
A level marks how far down a node sits, counted in steps from the top. The root sits at level 0. Its children are at level 1, their children at level 2, and so on.
In the example, the nodes form four horizontal bands: level 0, level 1, level 2, and level 3. All nodes that line up in the same horizontal band share the same level.
Depth
The depth of a node is the number of edges on the path from that node up to the root.
In the example, node a is two edges away from the root, so depth of node a = 2. Depth measures how far a node is from the top. (For the way levels are counted here, a node's depth and its level are the same number.)
Height
The height of a node is the number of edges on the longest downward path from that node to a leaf below it.
- Every leaf has a height of 0, because there is nothing below it to travel to.
- The height of the root is also called the height of the whole tree.
In the example, the longest path from the root down to a leaf crosses 3 edges, so height of root node = 3.
A handy way to remember the difference: depth looks upward toward the root, while height looks downward toward the farthest leaf.