Finding the Busiest Time Slot Among Overlapping Meetings
The Busiest Interval Problem
Imagine you run a meeting room booking system. People schedule meetings, and each meeting has a start time and an end time. Sometimes meetings happen at the same time, so several of them "overlap." The question we want to answer is: at what point in time are the most meetings happening at once, and how long does that busy stretch last?
That stretch of time is what we call the busiest interval.
What the input looks like
You are given a list of meetings. Each meeting is a pair of numbers: a start time and an end time. We write them like this:
[[s1, e1], [s2, e2], ...]
For every meeting, the start always comes before the end. In other words, si < ei. A meeting can't end before it begins — that just makes sense.
What "overlap" means here
Two meetings overlap when one is still going on while the other has already started.
The rule given to us is precise: two intervals [s1, e1] and [s2, e2] overlap only if e1 > s2.
There is an important edge case to notice:
- If
e1 == s2, the meetings are NOT considered overlapping.
Think about it in real life. If one meeting ends exactly at 3:00 and the next one starts exactly at 3:00, they don't actually clash — one person walks out the door as the next walks in. They just touch at a single point. So we treat "touching" as *not* overlapping. Only a real time conflict counts.
What you must return
Your job is to write a function that returns the busiest interval in this exact form:
[intervalStart, intervalEnd]
This is the time window during which the maximum number of meetings are happening together.
A few rules to handle special situations:
- Ties: If more than one time window has the same maximum number of overlapping meetings, return the first one (the earliest in time).
- No overlaps at all: If no meetings ever overlap, return
[-1, -1]. This is a special "nothing found" signal.
The starting code
The problem gives you a C++ class to fill in:
using namespace std;
class Solution {
public:
pair<int, int> busiestInterval(vector<vec
};The function busiestInterval takes the list of meetings and returns a pair<int, int> — which is simply the two numbers intervalStart and intervalEnd packaged together.
How to think about solving it
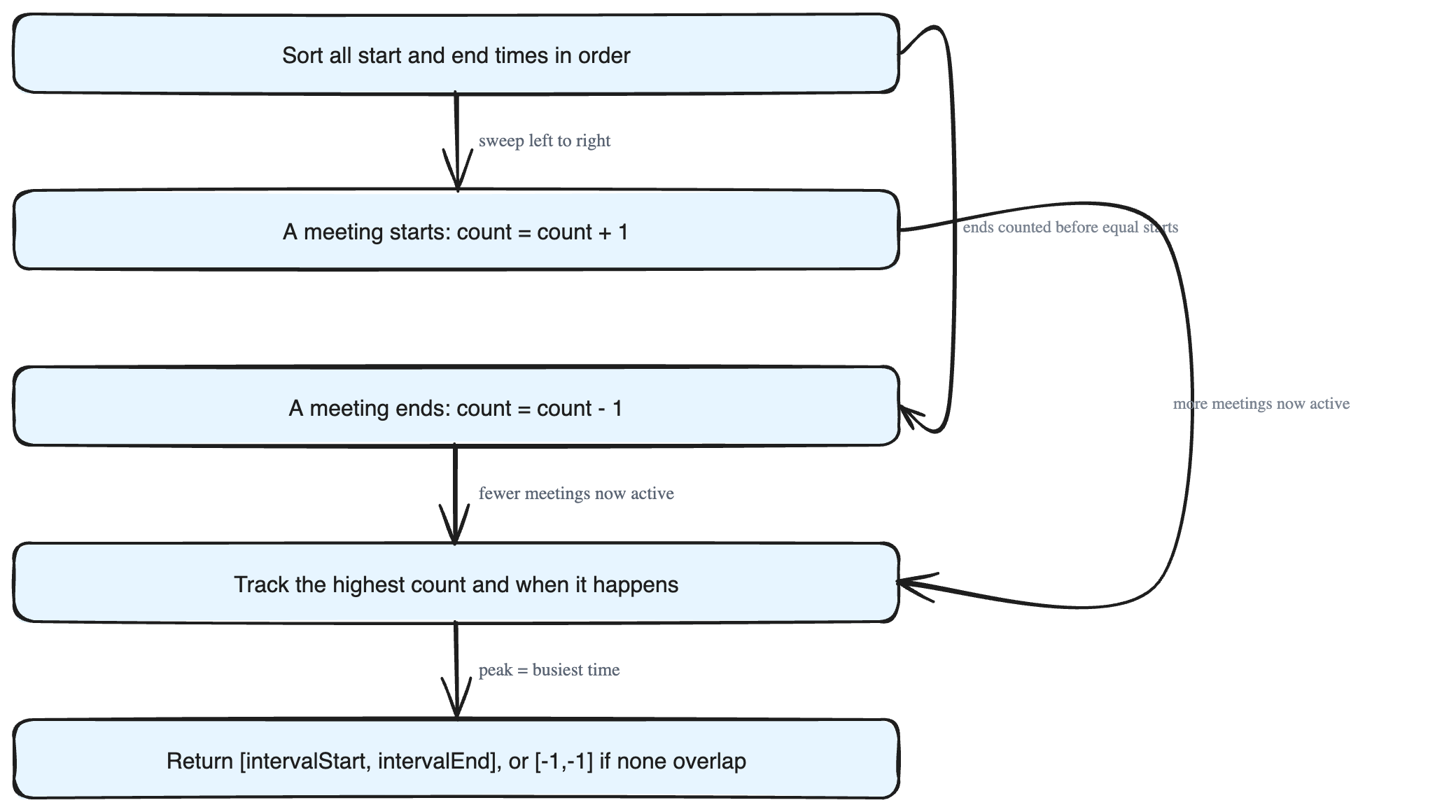
A common and intuitive idea is to imagine walking along the timeline and keeping a counter:
- Every time a meeting starts, more activity is happening, so add
1to your counter. - Every time a meeting ends, that activity is over, so subtract
1.
As you move forward in time, watch when the counter reaches its highest value. That moment — and the slice of time where it stays at that peak — is your busiest interval. Because we must respect the rule that touching meetings (end == start) do not overlap, you process an *ending* before a *starting* when they share the same time value. This is the classic "sweep line" idea, and it lets you find the answer efficiently.