Finding the Maximum Overlap with the Line Sweep Technique
Finding the Maximum Number of Overlapping Intervals
Imagine you run a small meeting room. People book it for time slots like "2 to 5" or "3 to 7". At some moments, several bookings overlap at once. A natural question is: what is the largest number of bookings happening at the same time? That number tells you the busiest moment.
In programming we call each booking an interval — a pair of two numbers, a start and an end. Our goal is to find the maximum number of intervals that overlap at any single point.
Let's use this example list of intervals:
arr = { (2,5), (5,9), (3,7), (1,4) }The answer here is 3 — at some moment, three of these intervals are active together.
The slow idea (and why we avoid it)
You could compare every interval with every other interval to see which ones touch. That works, but it uses nested loops (a loop inside a loop), which is slow and messy. There is a much cleaner idea.
The clever idea: turn intervals into points
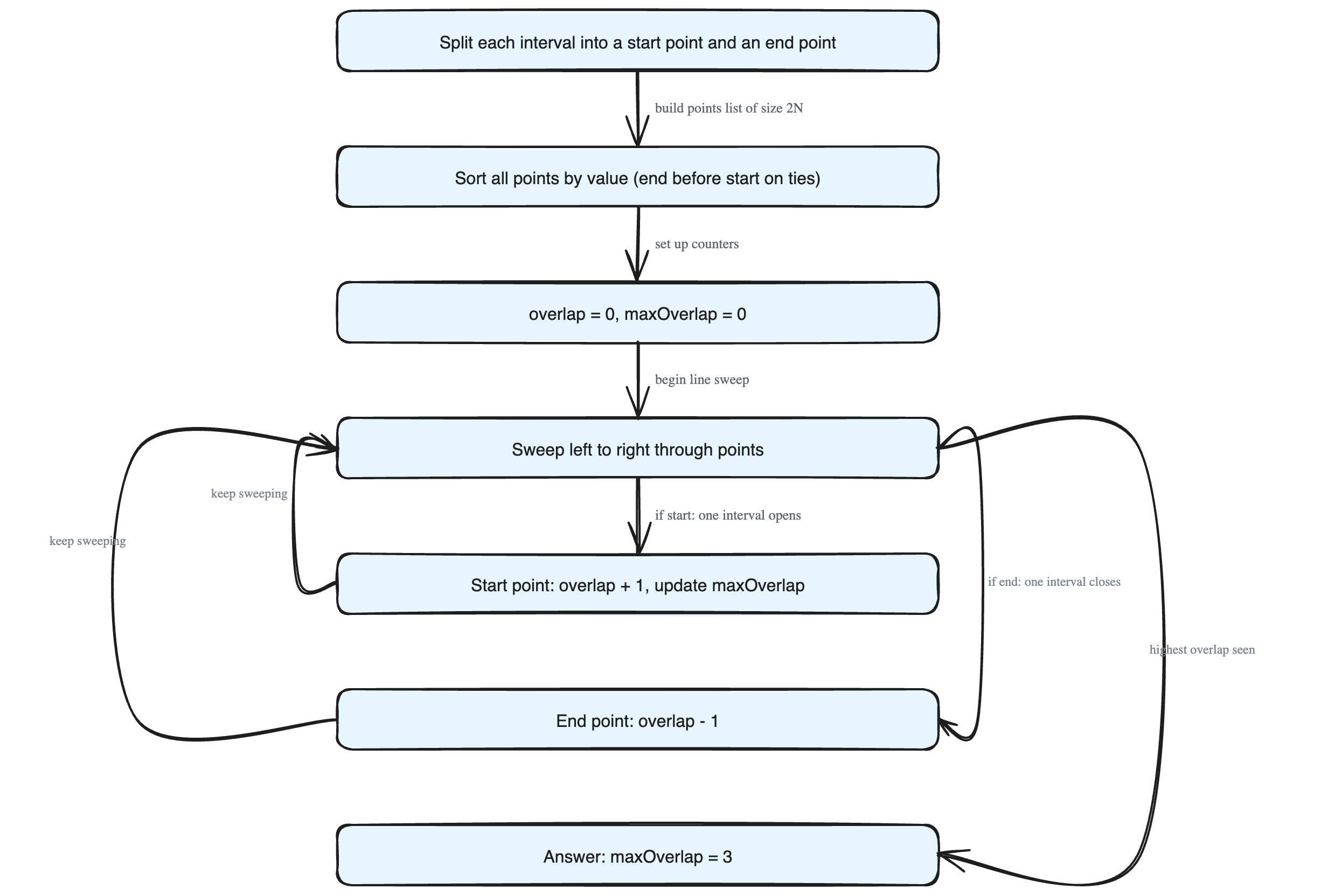
Think of a number line (the x-axis). Each interval is just a segment sitting on this line. An interval "opens" at its start and "closes" at its end.
So instead of thinking about whole segments, we only care about the moments things change — the start points and the end points. We break every interval into two separate points and remember which kind each one is.
From arr we build a points list. Each interval (start, end) gives us two entries:
(start, "start")(end, "end")
For our example, points becomes:
(2, start) (5, end) (5, start) (9, end) (3, start) (7, end) (1, start) (4, end)Sort the points
Now we sort the points by their value, from smallest to largest. Sorting lets us walk through time in order, left to right.
There is one important tie-breaking rule:
> If a start point and an end point have the same value, the end comes first.
Why? Because if one booking ends exactly when another begins, they are not really happening together. Closing the old one before opening the new one keeps the count honest. (A neat trick used in the code: the letter 'e' comes before 's' in the alphabet, so plain sorting of (value, char) pairs already does this for us.)
After sorting, the points are:
(1, start) (2, start) (3, start) (4, end) (5, end) (5, start) (7, end) (9, end)Sweep a line across the points
Now picture a vertical line sliding from left to right across the number line. This is the line sweep. As it touches each point, it reacts:
- Touch a start point → one more interval just opened → increment
overlapby 1. - Touch an end point → one interval just closed → decrement
overlapby 1.
We keep two counters:
overlap— how many intervals are open *right now*. Starts at0.maxOverlap— the biggestoverlapwe have ever seen. Starts at0.
Every time we open an interval, we check: is overlap bigger than maxOverlap? If yes, update maxOverlap. (We only need to check after a start, because the count only grows at a start.)
Walking through the example
Watch the counter rise and fall as the line moves:
| Point seen | Action | overlap | maxOverlap |
|---|---|---|---|
| 1 start | +1 | 1 | 1 |
| 2 start | +1 | 2 | 2 |
| 3 start | +1 | 3 | 3 |
| 4 end | −1 | 2 | 3 |
| 5 end | −1 | 1 | 3 |
| 5 start | +1 | 2 | 3 |
| 7 end | −1 | 1 | 3 |
| 9 end | −1 | 0 | 3 |
The highest the counter ever reached was 3, so maxOverlap = 3. That is our answer.
One small safety rule: it takes at least two intervals to call something an overlap. So if maxOverlap ends up less than 2, we set it to 0 — it means nothing actually overlapped.
The algorithm in steps
- Create a list
pointsand store the start and end of every interval (tagged as start or end). - Sort
pointsin non-decreasing order. On ties, end before start. - Set
overlap = 0andmaxOverlap = 0. - Walk through
points:
- If it is a start →
overlap++, then updatemaxOverlapif needed. - If it is an end →
overlap--.
The code (C++)
int maximumOverlap(vector<vector<int>> &intervals) {
// Create a dynamic array to store points
vector<pair<int, char>> points;
for(auto& interval: intervals) {
// Add start and end points to the points array
points.push_back(make_pair(interval[0], 's'));
points.push_back(make_pair(interval[1], 'e'));
}
// Sort the points array, end points come before
// start points as 'e' < 's'
sort(points.begin(), points.end());
// Initialize 'overlap' and 'maxOverlap' to 0
int overlap = 0, maxOverlap = 0;
for(auto& point: points) {
// ... increment on 's', decrement on 'e'
}
}Notice how the 'e' < 's' trick quietly handles the tie-breaking rule for free.
How fast is it?
- We make a
pointslist of size2 * N, whereNis the number of intervals. - Sorting that list costs O(N log N) time.
- Walking through it once costs O(N) time.
- The sort dominates, so the total time is O(N log N).
- We use extra space of size
2 * N, which simplifies to O(N) space.
This holds in both best and worst cases: Time O(N log N), Space O(N). That is a big improvement over the messy nested-loop approach, and it finds the busiest moment in a single clean pass.