The Interval Merging Pattern: Combining Overlapping Ranges
What is an interval?
An interval is just a range with a start and an end. For example, [3, 6] means "from 3 to 6". You can picture it as a line segment on a number line that begins at 3 and stops at 6.
Many real-life things are intervals: the time a movie plays, the hours a shop is open, or the period when a delivery is expected. When you have a whole list of these ranges, some of them often overlap — they share part of the same span. The interval merging pattern is a simple, reliable way to clean up such a list by gluing overlapping ranges into single, larger ranges.
When can you use this pattern?
This technique fits a very specific shape of problem. Watch for these signs:
- You are given an array of intervals (each one has a start and an end).
- Combining the ones that touch or overlap either solves the problem or gets you most of the way there.
If a problem matches this template, interval merging is the tool to reach for:
> Template: Given an array of intervals, merge all overlapping intervals.
These are usually easy or medium difficulty problems.
A worked example: delivery times
Problem: You are given the start and end times of expected deliveries during a day. Find the minimum number of non-overlapping time ranges such that, inside every range, at least one delivery is happening at all times.
The given times are:
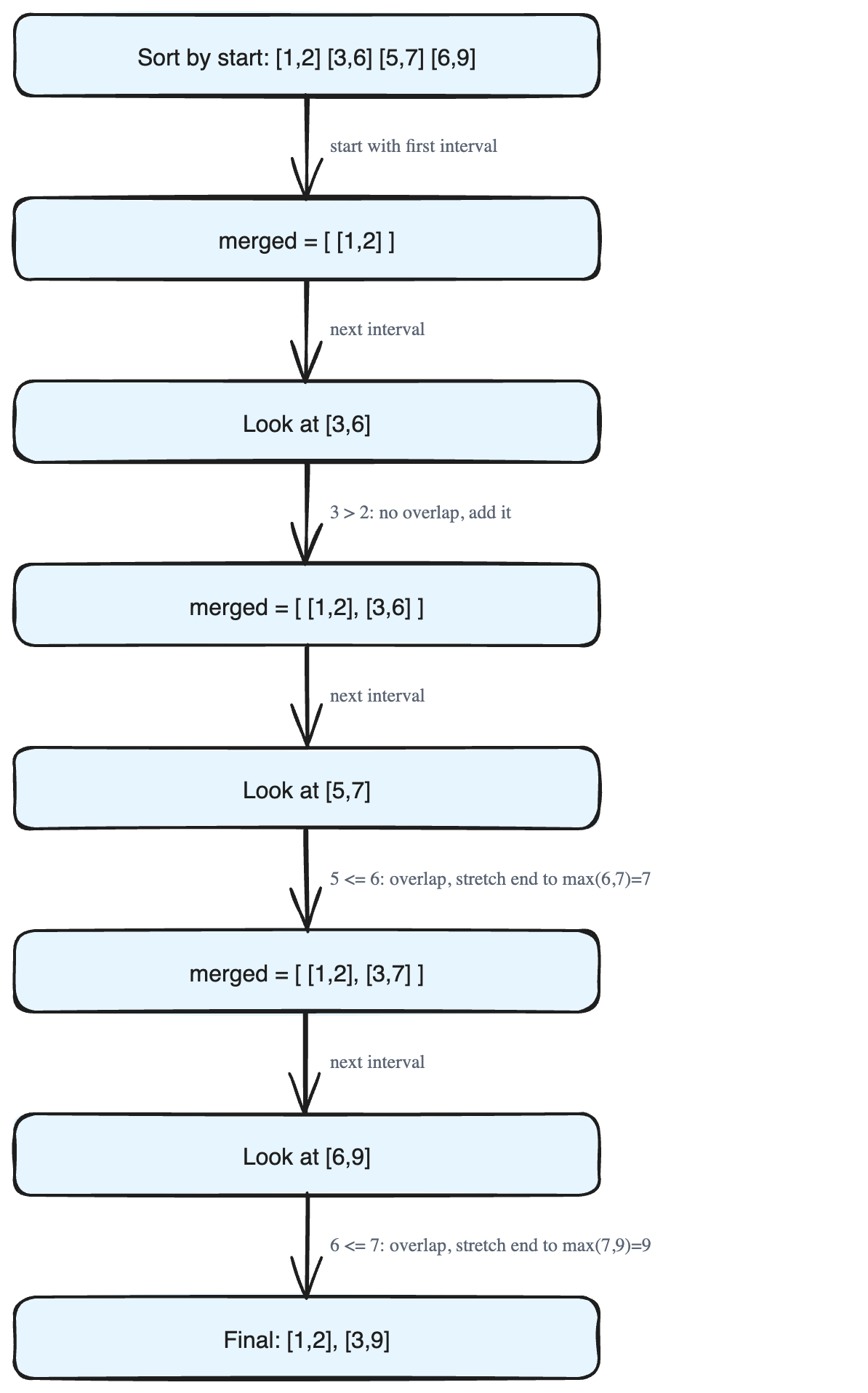
[5, 7] [3, 6] [6, 9] [1, 2]Why does merging solve this? If two delivery ranges overlap, then during that shared span deliveries never stop — so the two ranges are really one continuous busy period. After we merge all overlapping ranges, what remains are separate busy periods that do not touch. That count is automatically the *smallest possible* number of ranges, because we only kept ranges that genuinely cannot be combined any further.
Step 1 — Sort the intervals by their start time
Sorting is the trick that makes everything easy. Once the ranges are in order by where they begin, any overlap can only happen with the range right before it. We never have to look backwards more than one step.
After sorting, the array becomes:
[1, 2] [3, 6] [5, 7] [6, 9]Step 2 — Start the merged list with the first interval
Copy the first range into a new list called merged. This is our running answer.
merged = [ [1, 2] ]Step 3 — Walk through the rest, one at a time
Starting from index 1, look at each interval and compare it to the last interval in merged. There are only two cases.
Case A — No overlap. The new interval starts *after* the last merged one ends. They are separate, so just add the new interval to merged.
- Compare
[3, 6]with the last merged[1, 2]. Since3is greater than2, there is no overlap. Add it. merged = [ [1, 2], [3, 6] ]
Case B — Overlap. The new interval starts *at or before* the end of the last merged one. They touch, so we expand the last merged interval. We keep its start, and stretch its end to whichever end is larger.
- Compare
[5, 7]with the last merged[3, 6]. Since5is less than or equal to6, they overlap. Stretch the end:max(6, 7) = 7. merged = [ [1, 2], [3, 7] ]- Compare
[6, 9]with the last merged[3, 7]. Since6is less than or equal to7, they overlap. Stretch the end:max(7, 9) = 9. merged = [ [1, 2], [3, 9] ]
The final answer
[1, 2] [3, 9]Two non-overlapping ranges — the minimum needed.
The code
#include <algorithm>
using namespace std;
class Solution {
public:
vector<vector<int>> deliveryIntervals(vector<vector<int>> ×) {
// Sort times by start time
sort(times.begin(), times.end());
// Initialize output vector and push the first time
vector<vector<int>> merged = {times[0]};
// Loop through times and merge if overlapping or adjacent
for (int i = 1; i < times.size(); i++) {
// If the current time overlaps with the last time in
// the merged list, merge them
if (times[i][0] <= merged.back()[1]) {
merged.back()[1] = max(merged.back()[1], times[i][1]);
}
// else: add it as a new interval
}
return merged;
}
};The key line times[i][0] <= merged.back()[1] is the overlap test, and max(...) performs the expansion.
Why it is efficient
The work is dominated by the sorting step, which takes O(N log N) time. After that, we make just one pass through the array, which is O(N). So the overall cost is O(N log N) — fast and simple.
Where you will see this pattern again
The same idea solves a whole family of problems, such as:
- Verify schedule
- Overlap reduction
- Employee free time
- Insert interval
Once you recognize the "merge overlapping intervals" shape, all of these become approachable with the same sort-then-sweep recipe.