Simultaneous Traversal: Walking Through Two Arrays at the Same Time
Simultaneous Traversal: Walking Through Two Arrays at Once
When you have a single array, going through it is simple: you start at the first item and move forward one step at a time until you reach the end. But sometimes a problem gives you two lists of data, and you need to work with items from both lists together. The *simultaneous traversal* technique is how we do this — we walk through both arrays at the same time, in a single pass.
The Core Idea
Imagine two friends reading two different books side by side, comparing one page at a time. Each friend keeps a finger on their current page. After comparing, maybe one friend turns a page, maybe the other does, or maybe both do — it depends on what they just saw.
That is exactly the idea here:
- We have two arrays,
arr1andarr2. They can be different sizes. - We keep two "fingers" — two index variables,
index1for the first array andindex2for the second. - In each step, we look at the current item in each array (
arr1[index1]andarr2[index2]), apply some function or comparison, and then decide which finger to move forward.
The key difference from normal traversal: we don't blindly move both fingers every time. Based on a condition, we may advance only one of them, or both of them.
Why This Is Useful
Many real problems need this pattern. The classic example is merging two sorted lists into one sorted list. You look at the front of each list, take the smaller value, and move forward only in the list you took from. Other examples include finding common elements between two sorted arrays, or combining two sequences.
The big win is efficiency: instead of going through one array completely for every item of the other (which would be slow), you sweep through both just once.
How It Plays Out Step by Step
Picture both fingers starting at position 0:
- Compare
arr1[index1]witharr2[index2]. - Decide what to do based on your condition.
- Process the chosen item and move that finger forward.
- Repeat.
Sometimes index1 jumps ahead while index2 stays put. A few steps later it might be the opposite. Slowly, both fingers crawl toward the ends of their arrays. Because the two arrays have different lengths, one of them will usually run out first.
Handling the Leftovers
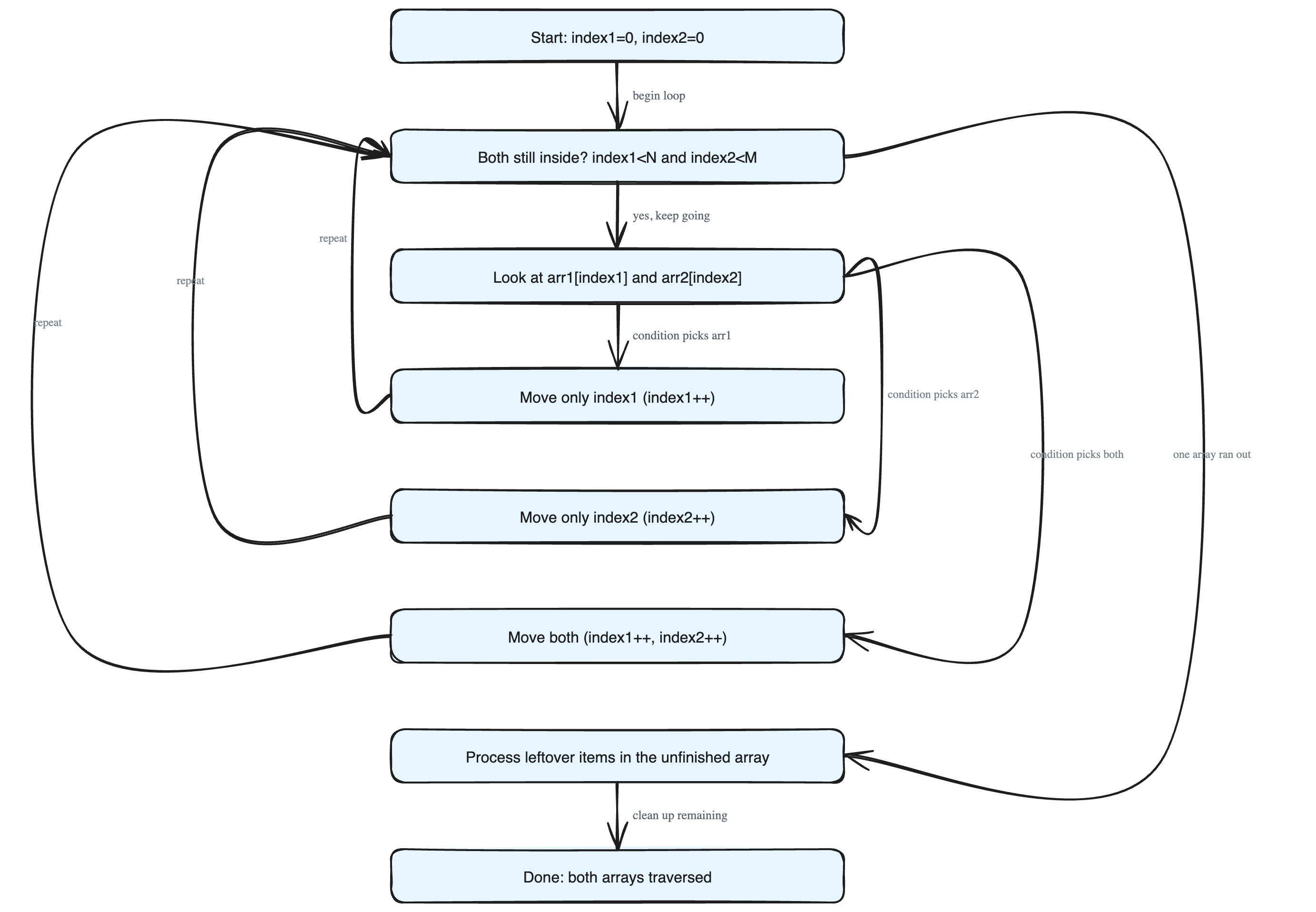
The main loop keeps going only while both fingers are still inside their arrays. The moment one array is fully used up, the loop stops — even if the other array still has items waiting.
So after the loop, we check: did one array still have leftover items? If yes, we simply walk through whatever remains in that array and process those items too. This "clean up the rest" step makes sure no data is missed.
The Algorithm
The version below moves from start to end in both arrays, advancing one step at a time:
- Step 1: Set
index1 = 0andindex2 = 0. - Step 2: Loop while
index1 < arr1.size()andindex2 < arr2.size(): - Step 2.1: Decide if you should move in the first array. If yes, process
arr1[index1]and incrementindex1. - Step 2.2: Decide if you should move in the second array. If yes, process
arr2[index2]and incrementindex2. - Step 3: If
arr1still has items left, walk through the rest usingindex1and process them. - Step 4: If
arr2still has items left, walk through the rest usingindex2and process them.
The Code (C++)
void simultaneousTraversal(vector<int>& arr1, vector<int>& arr2) {
// Initialize index variables for two arrays
int index1 = 0, index2 = 0;
// Traverse both arrays simultaneously until
// the end of any one array is reached
while(index1 < arr1.size() && index2 < arr2.size()) {
if(shouldMoveFirst) { // Replace this with actual condition
// Process arr1[index1]
// ....
index1++;
}
if(shouldMoveSecond) { // Replace this with actual condition
// Process arr2[index2]
// ....
index2++;
}
}
// (Afterwards, process any leftover items in whichever array is not finished.)
}Here shouldMoveFirst and shouldMoveSecond are placeholders. In a real problem you replace them with your actual rule — for example, "move in the array whose current value is smaller."
Variations
This pattern is flexible. You can change:
- Direction: go front-to-back in both, back-to-front in both, or mix the two.
- Step size: instead of moving one position at a time, you might hop several positions in each iteration.
The structure stays the same; only the details change.
Cost (Complexity Analysis)
- Time: Each array is fully scanned only once. If the arrays have sizes
NandM, the total work grows in line withN + M, so the time complexity isO(N + M)— linear. - Space: We only use two small index variables and create no extra data structures, so the space complexity is constant,
O(1).
This holds for both the best and worst cases, which makes the technique fast and memory-friendly.