How Row-Major Order Stores Multidimensional Arrays in Memory
Row-Major Order: Flattening an Array Into a Straight Line
When you write a 2D array in your head, you picture a neat table with rows and columns. But computer memory does not work like a table. Memory is just one long line of slots, placed one after another. So a question comes up: how do we fit a table-shaped array into a single straight line of memory?
Row-major order is the simplest and most natural answer to that question.
The core idea
Memory is linear — a single row of numbered slots, like a long shelf. A multidimensional array (a table, or even a cube of values) is a logical shape that lives only in our mind. To actually store it, we must *serialize* it: turn the table into one straight sequence.
Row-major order does this with one rule:
> Take the elements one full row at a time, and lay them down in memory side by side.
So all the elements of row 0 come first, then all the elements of row 1 right after them, then row 2, and so on. Elements that sit next to each other in a row end up next to each other in memory.
Think of reading a book: you read the entire first line left to right, then drop to the second line and read it left to right, then the third. You never jump up and down columns. Row-major order stores arrays in exactly that reading order.
Which languages use it?
Many popular languages store their multidimensional arrays in row-major order, including C, C++, and Objective-C. So this is not just theory — it is how your arrays really sit in memory when you program in these languages.
Walking through the process
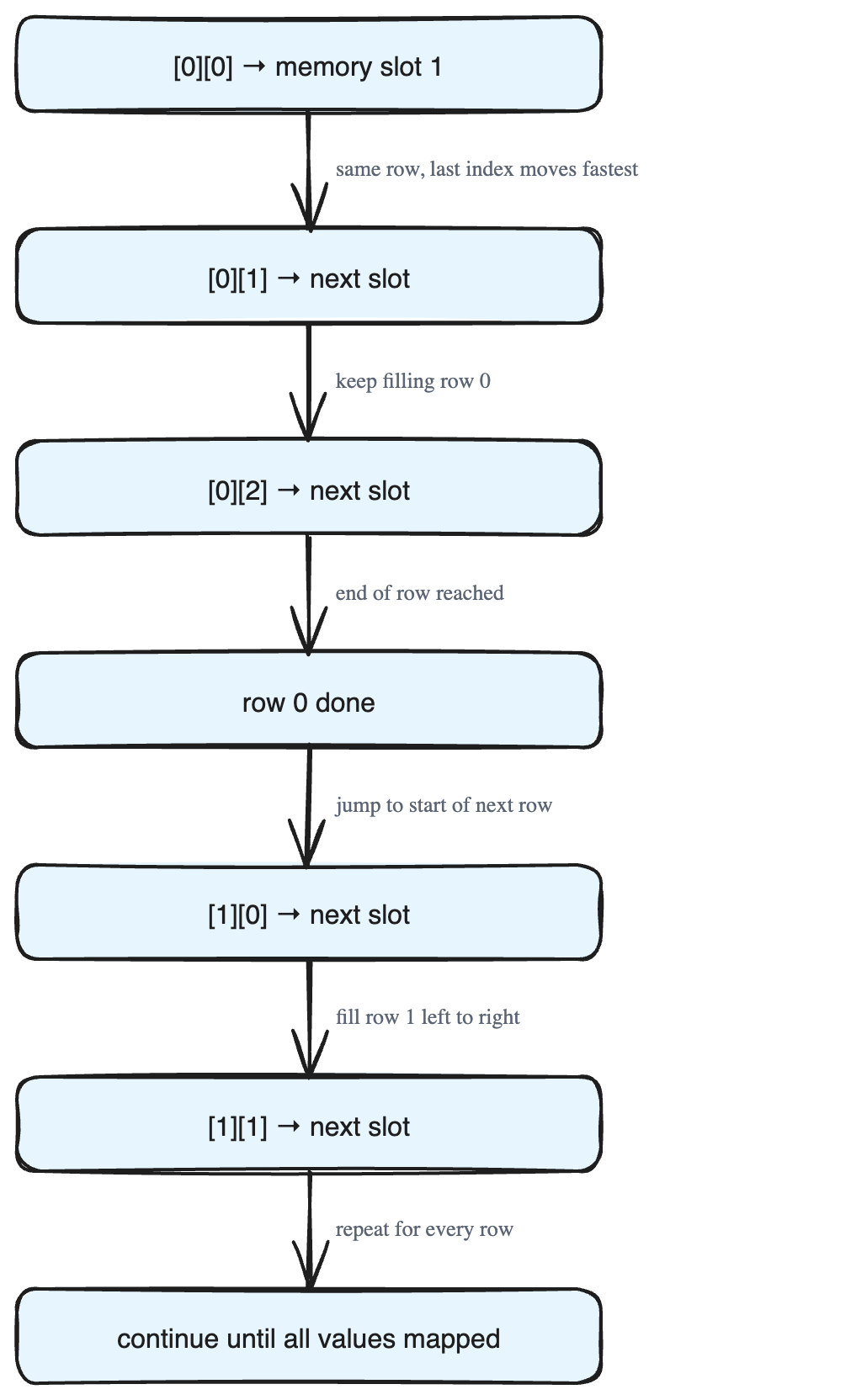
Imagine a 2D array drawn as a grid, and a long strip of memory slots numbered 0, 1, 2, 3, .... The array starts at a fixed point in memory called the base address (in the example, the base address is 2).
Now we copy values over, following row-major order:
- Start at the top-left of the grid: position
[0][0]. Place its value in the first free memory slot. - Move to
[0][1], the next element in the same row. Place it in the next memory slot. - Keep going:
[0][2],[0][3],[0][4]— still filling the same row, still filling consecutive memory slots. - When row 0 is finished, jump to the start of row 1:
[1][0]. Place it right after the last element of row 0. - Continue with
[1][1],[1][2], and so on, until every value is mapped.
This is what the phrase "the lowest dimension moves fastest" means. The last index (the column index j in [i][j]) is the one that changes on every single step. The earlier index (the row i) changes only after a whole row is done. The right-most index spins quickly; the left-most index crawls slowly.
Why "lowest dimension moves fastest" matters
This single rule scales to any number of dimensions. For an N-dimensional array with dimensions written as Dn x Dn-1 x ... x D1, you fill the array by increasing the last index I1 first. When I1 runs out, you bump the next index up by one and reset I1, and so on. The first index In moves the slowest of all. It is just like a car odometer: the right-most digit turns fastest, the left-most digit turns rarely.
Finding any element with a formula
Because the layout is so regular and predictable, we do not need to walk through memory to find an element. We can jump straight to it with a formula. If we know:
- the base address (where the array starts in memory),
- the size of each element (the base type size, in bytes), and
- the dimension sizes
Dn-1, Dn-2, ... D1,
then the address of the element at index [In][In-1] ... [I1] is:
address[In][In-1]...[I1] = base address
+ size of base type * ( In * (Dn-1 * Dn-2 * .... * D1)
+ In-1 * (Dn-2 * Dn-3 * .... * D1)
+ ....
+ I1 )In plain words: the big sum inside the brackets counts how many elements come before the one you want, in row-major order. Multiply that count by the size of one element to get how far to step forward in bytes, then add the base address to land exactly on your target.
Here is the intuition for the count. To skip past whole rows (or whole blocks in higher dimensions), you multiply each index by the size of everything that sits "below" it. For example, In * (Dn-1 * ... * D1) skips over In complete sub-blocks. The final + I1 then walks the last few steps within the current row. Add these up and you know the element's exact position — no searching required.
Key takeaways
- Memory is linear; a multidimensional array is not, so we must flatten it.
- Row-major order stores the array row by row, in reading order.
- The lowest (right-most) dimension changes fastest; the highest changes slowest.
- C, C++, and Objective-C use this order.
- Thanks to the regular layout, a simple formula gives the address of any element in constant time.